Pruebas con la lectura/escritura de ficheros en v7
El término (character encoding) codificación de caracteres define un conjunto de caracteres y cómo cada uno está representado dentro de un sistema de codificación. Para ser exacto sería necesario dejar claras ambas cuestiones.
Por un lado están los distintos conjuntos de caracteres que no son más que normas que definen cada carácter y su equivalente binario. Antiguamente estos conjuntos y los sistemas de codificación asociados eran distintos para cada necesidad (véase ASCII, EBCDIC, ISO-8859-x), hoy se tiende a unificar (véase Unicode y UCS) para resolver las distintas problemáticas con un mismo estándar.
Por otro lado se encuentran las distintas codificaciones que no son más que el orden numérico de las asignaciones.
Aclarando conceptos
Vamos a realizar un ejemplo para intentar aclarar estos conceptos sobre la codificación de ficheros.
Cogemos el notepad y realizamos un documento que contiene lo siguiente
HOLA MUNDO Y ÑÑÑÑ!”·$%&/()=?=)(/&%$·”!^*^ǨÇ:;_;:
y lo guardamos con tres encodings/codificaciones distintas. ANSI, Unicode y UTF-8
 Al abrirlos desde el notepad el los lee todos ellos correctamente, pero si los editamos con un editor hexadecimal…
Al abrirlos desde el notepad el los lee todos ellos correctamente, pero si los editamos con un editor hexadecimal…
Descargar editor hexadecimal – freeware
…veremos que son distintos, están codificados de forma diferente.
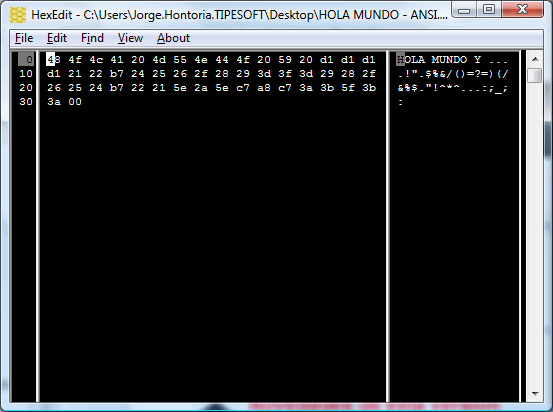
ANSI
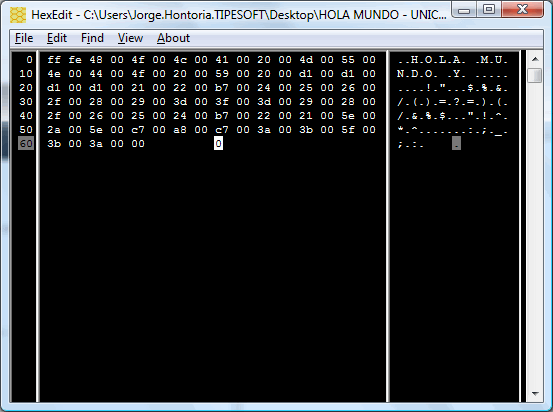
UNICODE
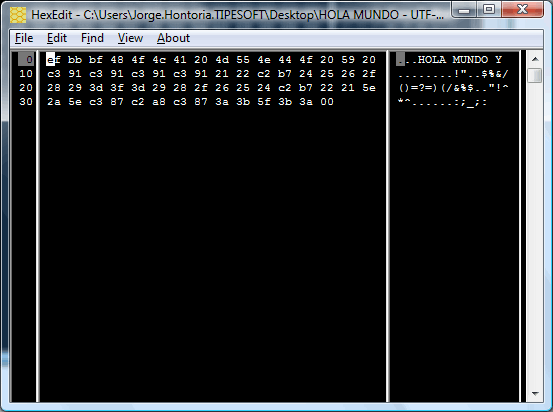
UTF-8
¿Cómo funciona Velneo a la hora de leer/escribir ficheros?

Resultado: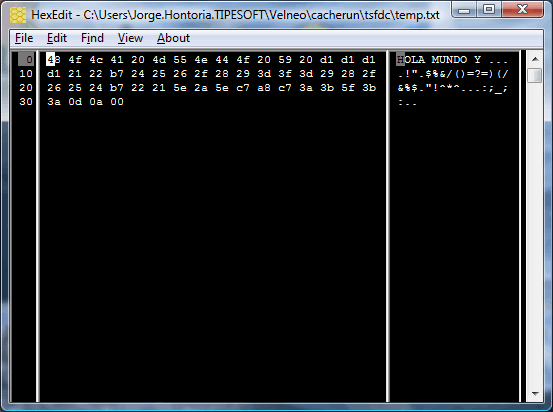
Si os fijais es identico al primer fichero creado en el ejemplo anterior, ANSI.
Veamos como lo lee si esta en ANSI…

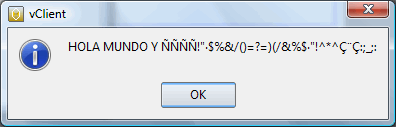
Perfecto…
Ahora realicemos un segundo ejemplo, sustituyendo ese mismo fichero por el codificado en UTF-8.
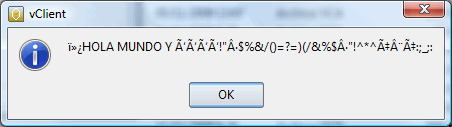
Pues sencillo, el es incapaz de detectar la codificación y lo trata como ANSI mapeando incorrectamente las asignaciones…
En resumen… Velneo siempre trata la lectura/escritura de ficheros en ANSI. Si queremos trabajar con ficheros externos hay que tenerlo muy en cuenta.
Sería muy recomendable que estas funciones permitan establecer en que codificación se van a leer/escribir los ficheros. Ya que si no, nos tocaría transformar las lecturas posteriormente a las codificaciones adecuadas o tratarlas para que en origen siempre estén codificadas en ANSI.
One Comment